Journal des Lycées > L'actualité des lycées
> Loire-Atlantique > Lycée Notre Dame d'Espérance > Les articles > Mais dis moi Jamy, c'est quoi le « Deep Learning » ?
Lycée Notre Dame d'Espérance, Saint-Nazaire, le 29/08/2019.
Mais dis moi Jamy, c'est quoi le « Deep Learning » ?
")

« Une technologie d'intelligence artificielle qui permet aux ordinateurs de résoudre des problèmes, sans avoir été explicitement programmée pour, via l'expérience et/ou l'utilisation d'une base de données. » Serait une définition générale du Machine Learning, pour les plus chauvins en français : Apprentissage automatique. Depuis plusieurs décennies déjà, la science de l'apprentissage automatique améliore et met au point des algorithmes pour reconnaître des paternes et faire des prédictions.
C'est l'un d'eux, le perceptron, qui constitue la base de l'apprentissage profond.
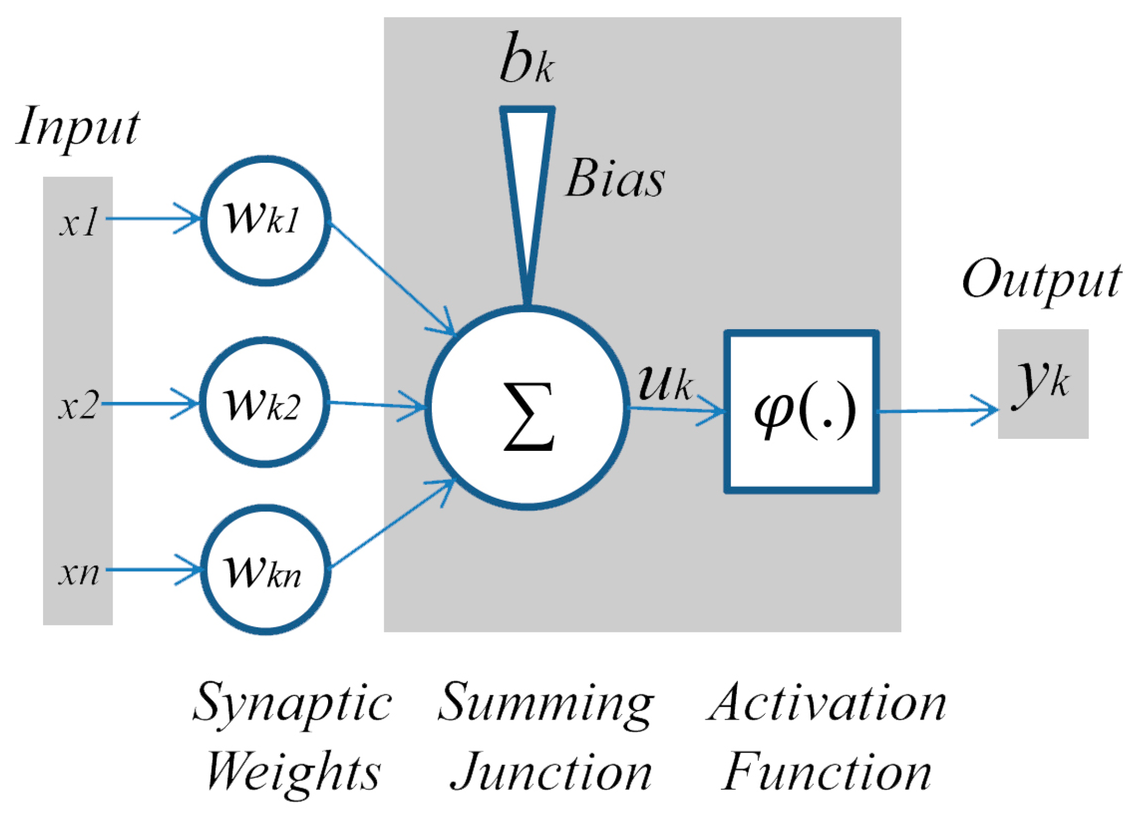
Perceptron Pour le définir diligemment : le perceptron est un algorithme qui sert à classifier des données et faire des prédictions dans un problème de complexité linéaire en appliquant une fonction d'activation sur la somme de ses entrées multipliée par leur poids correspondant.
Un algorithme est une suite finie d'instructions et/ou d'opérations formant une méthode générale pour résoudre un problème. Ici le problème est dit de complexité linéaire ; signifiant que la fonction O(n) donnant le temps pour résoudre un nombre de calcul n, est linéaire. Dit de manière simple, le perceptron est conçut pour résoudre des problèmes requérant des petits calculs.
Pour fonctionner il reçoit une ou plusieurs valeurs, ses entrées. Chaque entrée suit un chemin à part et à chaque chemin est déjà associé une valeur par laquelle l'entrée est multipliée, le poids. Les produits sont sommés, et le nombre N ainsi obtenu est passé dans une fonction visant à le contenir dans un intervalle, c'est la fonction d'activation. Par exemple, la fonction tangente hyperbolique d'intervalle [-1 ;1] ou bien la souvent citée fonction logistique, [0 ;1]. A noter que l'on ajoute parfois un biais à N, celui-ci peut être positif ou négatif.
Comme un neurone qui délivre une décharge en fonction des stimulations reçues, le perceptron sort une valeur qui dépend de celles entrées d'où le surnom de neurone artificiel. Toutefois, on remarque que les entrées n'auront pas toute la même influence sur la sortie, pour cause, le poids qui va en quelque sorte donner l'importance d'une connections en jouant sur l'intensité avec laquelle se propage l'information.
Problème Imaginez que vous pêchez et souhaitez savoir ou lancer votre magnifique bouchon rouge au milieu d'un sublime lac aux reflets d'or-azur, dans le but évident et noble de choper des grosses truites... Dans cette situation hypothétique, disons que vous eussiez disposé d'un disque dur répertoriant les zones les plus poissonneuses. Cette base de donnée considère le lac comme une surface quadrillée où chaque case possède à la fois des coordonnées (x ;y) et un pourcentage de réussite établit grâce aux témoignages de pêécheurs.Le problème est que vous ne voulez pas emmener votre disque dur et votre pc à chaque fois que vous irez pécher, donc pour cela vous allez entraîner un perceptron à prédire si une zone sera poissonneuse où non.
Apprentissage Le perceptron est initialisé avec 2 entrées pour les coordonnés (x ;y), des poids aléatoires et un biais nul. Pour simplifier la tâche on considère qu'une zone est poissonneuse lorsque son taux de réussite est supérieur à 70 %. Notre fonction d'activation sera la fonction Tan H. Une valeur de sortie 1 s'interprète comme la prédiction d'une zone poissonneuse et une valeur -1 comme non-poissonneuse.
On entre x & y, puis on regarde si la prédiction correspond à notre base de donnée, si oui, rien ne change, sinon on va chercher à corriger nos poids. Pour cela on calcule le coût, la valeur de la marge d'erreur. Le coût s'écrit : résultat attendu moins résultat obtenu ; il le faut le plus proche possible de 0. Exemple : la prédiction est -1 et la base de donnée donne 1, le coût est égal à -2 (= -1 -1).
Il suffit alors de multiplier les poids par une fraction du coût, puis de réitérer avec de nouvelles coordonnées jusqu'à ce que les prédictions du perceptron soient toujours juste (ou presque).
Conclusion & réseaux de neurones Une fois entraîné, l'emploi du perceptron demande peu de ressource, fonctionne sans base de donnée et hors connections, et est généralement d'une grande précision. Bref ! c'est tout bénèf.
Cependant la phase d'entraînement, elle, est longue demandant une forte puissance de calcule et surtout une grande base de donnée uniformisée pour une précision optimale. Alors évidement il existe d'autres réponses sûrement plus efficaces à ce problème de pêcheur.
Toutefois des cerveaux avec un seul neurone ça n'existe qu'en dehors de la filière S... pour la réalisation de tâches complexes on va faire appel à un réseau de neurones inter-connectés. Il en existe de nombreuses architectures, parfois évolutives, la plus conventionnelle étant le réseau multi-couche. Ce réseau est construit en plusieurs couches (thanks captain obvious), les neurones d'une couche étant reliés à tous ceux de la couche précédente. La première couche reçoit les inputs et la dernière fait la prédiction, entre les deux c'est la zones profonde (d'où "deep learning" et ouais).
Dans le cas de réseaux de neurones, l'apprentissage se fait grâce aux équations de rétro-propagation du gradient qui permettent d'appliquer des corrections relatives au degré d'implication d'une connections dans l'erreur de prédiction.
Cette méthode trouve un fondement biologique dans le phénomène de rétro-propagation neuronale, quand l'influx nerveux se propage vers les dendrites dont il venait au départ.
Yoann CABEL.
C'est l'un d'eux, le perceptron, qui constitue la base de l'apprentissage profond.
Perceptron Pour le définir diligemment : le perceptron est un algorithme qui sert à classifier des données et faire des prédictions dans un problème de complexité linéaire en appliquant une fonction d'activation sur la somme de ses entrées multipliée par leur poids correspondant.
Un algorithme est une suite finie d'instructions et/ou d'opérations formant une méthode générale pour résoudre un problème. Ici le problème est dit de complexité linéaire ; signifiant que la fonction O(n) donnant le temps pour résoudre un nombre de calcul n, est linéaire. Dit de manière simple, le perceptron est conçut pour résoudre des problèmes requérant des petits calculs.
Pour fonctionner il reçoit une ou plusieurs valeurs, ses entrées. Chaque entrée suit un chemin à part et à chaque chemin est déjà associé une valeur par laquelle l'entrée est multipliée, le poids. Les produits sont sommés, et le nombre N ainsi obtenu est passé dans une fonction visant à le contenir dans un intervalle, c'est la fonction d'activation. Par exemple, la fonction tangente hyperbolique d'intervalle [-1 ;1] ou bien la souvent citée fonction logistique, [0 ;1]. A noter que l'on ajoute parfois un biais à N, celui-ci peut être positif ou négatif.
Comme un neurone qui délivre une décharge en fonction des stimulations reçues, le perceptron sort une valeur qui dépend de celles entrées d'où le surnom de neurone artificiel. Toutefois, on remarque que les entrées n'auront pas toute la même influence sur la sortie, pour cause, le poids qui va en quelque sorte donner l'importance d'une connections en jouant sur l'intensité avec laquelle se propage l'information.
Problème Imaginez que vous pêchez et souhaitez savoir ou lancer votre magnifique bouchon rouge au milieu d'un sublime lac aux reflets d'or-azur, dans le but évident et noble de choper des grosses truites... Dans cette situation hypothétique, disons que vous eussiez disposé d'un disque dur répertoriant les zones les plus poissonneuses. Cette base de donnée considère le lac comme une surface quadrillée où chaque case possède à la fois des coordonnées (x ;y) et un pourcentage de réussite établit grâce aux témoignages de pêécheurs.Le problème est que vous ne voulez pas emmener votre disque dur et votre pc à chaque fois que vous irez pécher, donc pour cela vous allez entraîner un perceptron à prédire si une zone sera poissonneuse où non.
Apprentissage Le perceptron est initialisé avec 2 entrées pour les coordonnés (x ;y), des poids aléatoires et un biais nul. Pour simplifier la tâche on considère qu'une zone est poissonneuse lorsque son taux de réussite est supérieur à 70 %. Notre fonction d'activation sera la fonction Tan H. Une valeur de sortie 1 s'interprète comme la prédiction d'une zone poissonneuse et une valeur -1 comme non-poissonneuse.
On entre x & y, puis on regarde si la prédiction correspond à notre base de donnée, si oui, rien ne change, sinon on va chercher à corriger nos poids. Pour cela on calcule le coût, la valeur de la marge d'erreur. Le coût s'écrit : résultat attendu moins résultat obtenu ; il le faut le plus proche possible de 0. Exemple : la prédiction est -1 et la base de donnée donne 1, le coût est égal à -2 (= -1 -1).
Il suffit alors de multiplier les poids par une fraction du coût, puis de réitérer avec de nouvelles coordonnées jusqu'à ce que les prédictions du perceptron soient toujours juste (ou presque).
Conclusion & réseaux de neurones Une fois entraîné, l'emploi du perceptron demande peu de ressource, fonctionne sans base de donnée et hors connections, et est généralement d'une grande précision. Bref ! c'est tout bénèf.
Cependant la phase d'entraînement, elle, est longue demandant une forte puissance de calcule et surtout une grande base de donnée uniformisée pour une précision optimale. Alors évidement il existe d'autres réponses sûrement plus efficaces à ce problème de pêcheur.
Toutefois des cerveaux avec un seul neurone ça n'existe qu'en dehors de la filière S... pour la réalisation de tâches complexes on va faire appel à un réseau de neurones inter-connectés. Il en existe de nombreuses architectures, parfois évolutives, la plus conventionnelle étant le réseau multi-couche. Ce réseau est construit en plusieurs couches (thanks captain obvious), les neurones d'une couche étant reliés à tous ceux de la couche précédente. La première couche reçoit les inputs et la dernière fait la prédiction, entre les deux c'est la zones profonde (d'où "deep learning" et ouais).
Dans le cas de réseaux de neurones, l'apprentissage se fait grâce aux équations de rétro-propagation du gradient qui permettent d'appliquer des corrections relatives au degré d'implication d'une connections dans l'erreur de prédiction.
Cette méthode trouve un fondement biologique dans le phénomène de rétro-propagation neuronale, quand l'influx nerveux se propage vers les dendrites dont il venait au départ.
Yoann CABEL.
{kind=link}